Authored by Certified Business Psychologist Laura Howard. Certified Business Psychologist, Laura Howard, reflects on the webinar she recently delivered to ABP members. Below she outlines the main findings of her published research uncovering systematic barriers women face when being authentic as leaders. Importantly, she gives…

The interest in human intelligence has been traced back to the 7th century AD, but it wasn’t until the late 19th century that the modern study of intelligence began. Since Alfred Binet’s early pioneering work, aptitude tests to measure intelligence have become an essential recruitment tool for many organisations. But in an era of generative AI where our most valued human capability, intelligence, is outshone by a computer programme, we need to re-evaluate what we value, and how we measure it, in terms of human intelligence.
From the initial work around IQ at the start of the 20th Century, more and more intelligence tests started to emerge and by the 1950s psychometric tests began to be used to measure intelligence more broadly, morphing into the psychometric aptitude tests used widely in recruitment today. At the heart of it all is a societal worship of human intelligence, most evident in the revered membership of the IQ elite, MENSA. The interest in the role of intelligence in job performance was accelerated after the meta-analysis study by Schmidt & Hunter in 1998. Their study found that the single best predictor of performance in the workplace was general mental ability.
There are now hundreds if not thousands of different aptitude tests to choose from and millions of job applicants are put through them each year. This use has increased dramatically in the last few years as the reliability of educational grades, whether from schools or universities has declined significantly, so employers have had to find alternative means to measure the cognitive ability of applicants.
Despite their universal usage, more and more detractors are emerging about the efficacy, fairness and even relevance of the aptitude tests. Studies are emerging on the impact such tests have on the neurodiverse community and several academics are challenging whether these traditional tests capture the full range of human intelligence. Once such detractor is the American psychologist and psychometrician, Robert Sternberg, who ominously predicted in his 1985 paper, Beyond IQ:
“Our society, in placing so much emphasis on scores on standardised tests, is making a serious and possibly irreversible mistake.”
Add to this the emergence of generative AI tools like ChatGPT, which completes these tests faster than a human, and the time has come to rethink what we want to measure and how we measure it.
Traditional aptitude tests are heavily focused on processing information and constructed on a framework with multiple choice answers which give no room for candidates to demonstrate how they arrived at their answer. The lack of interactivity and format of traditional item types generates higher levels of anxiety which in turn impacts certain groups, especially those in the neurodiverse community. Rethinking the design of items to give greater interactivity addresses these issues and also opens up new scoring methods for further improvements. The diagram below is a useful visual of the difference:

Using this approach, Arctic Shores has been able to leverage its experience in task based assessments to create a new style of aptitude test where the user builds their answer to the item challenge (see below); in the diagram the box on the right is where the user works to select the correct shape, rotation, colour/pattern and size.
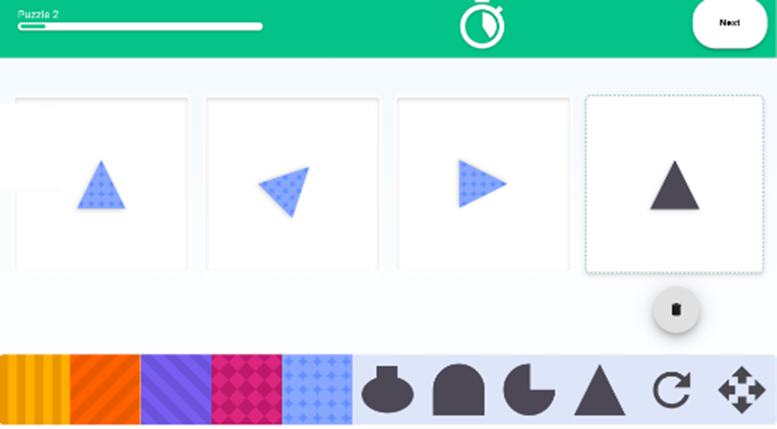
This interactivity improves test-taker’s experience and puts them at greater ease, all factors which reduce anxiety (e.g. Strain-Seymour, Way, & Dolan, 2009; Wendt & Harmes, 2009).
There is one further significant improvement. A task-based approach enables us to give partial credit to item solutions. This is a huge step in recognising how a user problem-solves and recognises the value in building the answer even if the final correct solution was not achieved.
The difference is significant. With a traditional item type where 20% get the item right and 80% wrong, there is no recognition for those in the 80% who got close to the answer – under our approach we found nearly one quarter of those that did not achieve the right answer, had 90% of the solution correctly identified. Not only does this support greater reliability, we found that adverse impact in key groups was reduced. This design approach also improves task reliability which in turn enhances its validity.
All in all this novel approach to item design for aptitude tests enables to both improve the way we capture information and expand the breadth of cognitive ability being measured ( research shows too that there is a further benefit in the removal of the influence of irrelevant variance Arendasy & Sommer, 2013; Becker et al., 2016).
When intelligence tests were first devised over a century ago, the primary attributes we prized were processing capability and speed of thought. Now that we have computers which process information at levels and speeds way beyond that of humans, we need to rethink which other elements of human intelligence and capability will be relevant to job performance. Already forward-thinking organisations are focusing on learning agility and emotional intelligence as the most prized capabilities. AI will not make the role of the knowledge worker redundant rather it will make the value a human can add different. Which is why we need to change what we assess for and how we assess for it.
Other References
Arendasy, M. E., & Sommer, M. (2013). Reducing response elimination strategies enhances the construct validity of figural matrices. Intelligence, 41(4), 234–243. https://doi.org/10.1016/j.intell.2013.03.006
Becker, N., Schmitz, F., Falk, A. M., Feldbrügge, J., Recktenwald, D. R., Wilhelm, O., Preckel, F., & Spinath, F. M. (2016). Preventing Response Elimination Strategies Improves the Convergent Validity of Figural Matrices. Journal of Intelligence, 4(1), 2. https://doi.org/10.3390/jintelligence4010002
Strain-Seymour, E., Way, W., & Dolan, R. (2009). Strategies and Processes for Developing Innovative Items in Large-Scale Assessments.
Wendt, A., & Harmes, J. C. (2009). Evaluating Innovative Items for the NCLEX, Part I: Usability and Pilot Testing. Nurse Educator, 34(2), 56. https://doi.org/10.1097/NNE.0b013e3181990849
Related Posts


